以前写scheme解释器时完全不去考虑垃圾回收,直接链接个libgc完事。因为当时觉得垃圾回收还是很神秘的,而且懒得花时间去调试内存,只想把解释器的功能赶紧实现了。没想到现在能有机会自己实现个垃圾回收。学校里上的编译课上要求实现一个简单的拷贝收集,而且最后一个大项目我也选择去实现一个分代垃圾回收,其中和垃圾回收有关的部分全部在这。
现在觉得垃圾回收真是很简单,而且也越来越觉得之前博客推荐的那篇关于垃圾回收的综述性论文很牛了,把所有垃圾回收都纳入同一理论,再推荐一次。
拷贝收集
拷贝收集算是垃圾回收中最简单的了,觉得coursera上的compiler课的17-03课就讲得很清楚了(不知道怎么分享coursera的视频),听完后就能自己实现一个了,具体实现这里就不说了。
这算法的好处就是时间复杂度只和活对象的数目有关,不像mark & sweep与堆大小有关。所以特别适合对垃圾比较多的堆进行收集,但是缺点就是会浪费一半内存。
分代垃圾回收
分代垃圾回收是基于两个观察:
- 大部分对象存活时间短
- 很少有年老对象指向年轻对象
第二个情形特别适用于函数式语言,在scheme中出现这种情况只可能是调用了set-car!和set-cdr!之类的函数了。不过就算是在java中这种情况也很少出现,所以就像为了利用局部性原理出现cache一样,也出现了利用这两种情景的分代回收。
术语
root
判断对象是否是垃圾的方法就是看程序能否引用到这个对象,程序访问对象有个起点,这个起点就是root,在C中root就是所有data段,bss段和stack段的指针。java中就是所有类的静态域和栈引用。
minor collect
由于大部分对象活的时间都比较短,所以空间很容易就塞满了垃圾,需要对年轻代进行收集,收集的起点就是root,但是不要忘了老对象也能指向年轻对象的,如果只看root而不看老对象的引用,那么就会回收非垃圾。但是老年堆一般又比较大,如果每次收集都要遍历一遍年老对象会非常慢。下面会说到几个方法可以加快年老对象的扫描这个过程。
major collect
如果对象能逃过几次minor collect那么根据之前的观察就有理由相信这个对象短期内不会变成垃圾,这样就能把它从年轻堆提升到年老堆,但是年老对象也总有变成垃圾的一天,这样就要对年老堆进行一次收集,这种收集就叫做major collect,由于需要扫描整个堆所以这个过程非常耗时,如果是用的stop the world方法,用户程序就会出现短暂的卡顿,如果卡顿明显就不能接受了,所以之后jvm的很多垃圾回收算法都只是为了缩短这个卡顿时间而已。
关于分代垃圾回收也有篇论文可以看,里面就讲到了怎么解决分代GC的一个关键问题:如何处理年老对象指向年轻对象这种情况,有使用类似操作系统脏页的方法还有种直接记录引用的方法。
堆间root
假设现在内存情况如下图
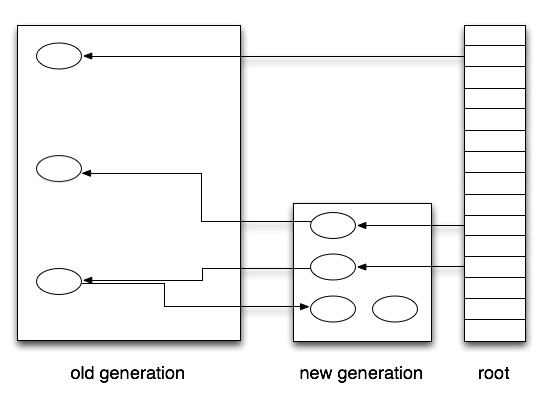
如果在进行minor collect时只考虑root会出现什么情况?年轻代左下角的对象就会被当做垃圾被回收,结果就是程序执行结果不对。而且这种bug完全没法调试。但是如果在进行minor collect时扫描一遍年老堆,性能就不可能好,因为一般来说年老堆都会比较大。
前面说的关于分代垃圾回收的那篇论文就有个算法来解决这个问题,需要特殊硬件来处理,类似于现在操作系统页表的脏位,只是这个脏位并不是在每次写时置1,而是在每次将年轻代地址赋值给年老代时才置1。这个需要特殊硬件支持,貌似是当年lisp机器的硬件,不过这种方法也可以拿软件模拟,如下图。
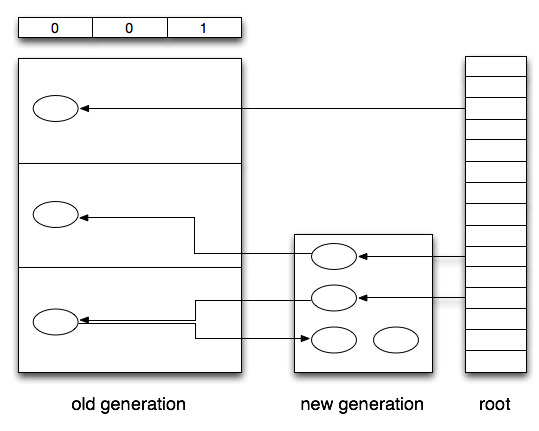
这时年老堆被分成三块,上面的表中数字就表示对应的年老堆中是否有对年轻堆的引用。所以在进行minor collect时不仅仅需要考虑普通的root也需要考虑这种堆间root,在上图中,这种情况就还需要扫描年老堆的第三个部分。这样年轻堆的左下角的对象就不会被当成垃圾被回收。这种方式如果需要软件来模拟就需要编译器在每条赋值语句后都插一条函数调用,这个函数需要判断参数是不是将年轻对象的引用赋值给年老对象,如果是则需要给相应位置1。
不过既然使用软件来做,就完全可以把范围缩得更小,因为前面的方法还是需要扫描堆的很大一个部分,所以我在实现时就直接记录了年老对象的地址,这样在minor collect时只需要扫描对应对象的引用就行,我是拿链表实现的,并对链表进行了排序。拿链表做主要是因为之前说的年老对象指向年轻对象的情况虽然有但是还是很少,不过更好的数据结构应该是红黑树,但是我就不做这么复杂了。而且在没有确切证据说链表不适合这种工作时还是没必要在这里进行优化,因为链表实现起来实在很简单。这个方法也需要编译器在每条赋值语句后插入条和前面说的类似的函数调用。
mark & compact
在进行major collect时我使用的是mark & sweep算法,用这个算法有个顺带的好处就是可以直接使用相关的碎片整理算法。之前觉得碎片整理很复杂,但是去搜,发现有mark & compact算法了,它有个LISP2算法很简单(lisp的历史遗产真不是一般的多)。我的实现是在每次major collect时都要进行一次碎片整理,但是应该可以不需要这么频繁,如果真需要把这东西实际用起来,这里应该可以优化成少做几次compact。
内存分配方式和策略
我的实现需要年老堆必须是一块连续的内存地址,之前还有段时间纠结怎么获得连续的空间,因为设计的年老堆是可以根据需要动态分配内存的,如果每次分配都调用mmap(2)来分配就必须用上它的第一个参数并加上MAP_FIXED标志,但是这样做很不靠谱,一旦第一次mmap(2)给的地址接下来的几页马上就是其他已经被使用的地址,那么mmap就会失败,这种情况也是很容易发生的,不能依赖这种情况。在豆瓣上问了下后就有答案了(谢谢@dutor给的建议):在初始化时使用mmap(2)分配尽可能大的内存空间,因为大部分系统都使用惰性分配,所以不会有问题,但是在写了这些内存区域后操作系统就不知道这块内存是不是会再被用到,如果应用确定不需要用到时再调用madvise(2)并加上MADV_DONTNEED就能在保持地址空间的前提下释放内存,下次再需要时再调用madvise(2)加上MADV_WILLNEED即可。
对于用户程序的内存请求,这个实现是直接从年轻代分配,如果能分配成功,那么速度会非常快,因为只是需要对指针进行一次加法即可。但是如果年轻代空间不够时就需要进行一次minor collect,每进行一次minor collect就会对每个活对象的扫描次数增一,一旦达到阈值就会将对象提升到年老堆。年老堆会准备一定空间进行拷贝,如果年老堆的空间也不够就会调用一次major_collect,但是并不是每次调用major_collect都会真正进行major collect,我设置了一个时间域。如果上次major collect离这次不久就不做任何事,如果这样空间还是不够就会按照前面说的调用madvise(2)进行分配。再不够就OOM了。
实际上jvm也基本上是这么做的,只是jvm是在一个叫Eden堆的地方分配,该堆满了后拷贝到survive区,survive区就完全和我的年轻堆一样,有一个大小一样的from和to区,但是jvm的Eden堆的大小是from区和to区的几十倍,因为有论文指出年轻堆中会有98%的垃圾,只有2%能存活下来,所以Eden堆满了后把所有活对象拷贝到from区,也只需要拷贝Eden堆的2%,这样from区和to区的大小基本上只需要Eden堆的2%即可。这样看来前面说的拷贝算法会浪费一半内存其实根本没什么。一个真正的系统就是要结合各种算法的优点,避免它们的缺点而已,重要的还是权衡这些算法。
现在的实现还是有点问题就是即使最后没内存了也不一定是真没内存,因为有的OOM是对对象进行提升时导致的,如果不进行提升也就不会导致最后的OOM,而且相对于OOM,能不提升就不提升吧。所以这个也是这个实现需要改进的部分。
现在感觉mark & sweep的mark部分完全可以和用户程序并行跑,就算是sweep部分只要处理得小心也能大部分并行跑。所以有个后台的垃圾回收器会显著减少卡顿时间。
在我真正开始写代码前我花了一整天的时间去考虑各个函数间的关系,以及算法的正确性,因为这种内存管理的代码一旦出错调试就会很麻烦,但是这个验证的过程也相当于熟悉算法的过程了。能掌握很多细节,而不是在调试中去痛苦地掌握,你一生至少应该经历一次。
