垃圾收集是高级编程语言最重要的一部分,不过垃圾收集是否值得也要看具体应用,我就很同意这个观点。最近写了个玩具lisp解释器,由于不想自己去管理所有内存,所以用了libgc库,也顺便了解了下GC的一些技术。
而对于垃圾收集有两种最基本的方式:reference count和tracing。更多的变种见此。
Reference Count
reference count是最简单垃圾收集的方法,内核的代码就是手工模拟该算法的,而一些有虚拟机的语言就直接使用了该算法,例如CPython。
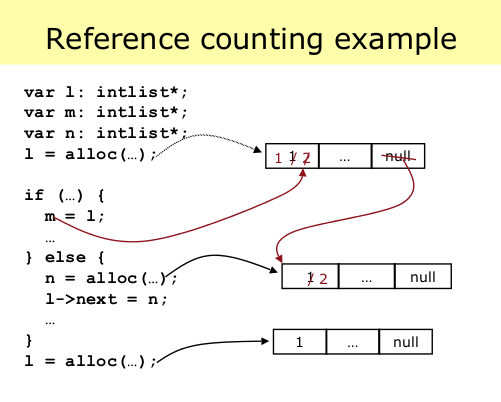
如果使用引用计数方法,那么所有的在堆上的对象都会多一些空间用于记录对该对象的引用数,见上图。并且该方法需要编译器或者解释器的特殊支持,否则上图中m = l语句和l->next = n语句就无法修改对象的引用计数(所以C中没有使用这种算法的库)。并且RC方法有个最不好的一面就是无法收集环状的垃圾。例如以下语句:
struct intlist *j, *k; j = alloc(); k = alloc(); j->next = k; k->next = j; j = k = NULL;
在以上语句执行完后在堆上应该没有任何东西,但是之前j和k所指向对象的引用计数却都是1(因为互相指向对方),所以单纯的引用计数的方法无法收集环状垃圾,这是它致命的缺点。它还有个缺点就是效率不高,因为每次对指针进行修改和赋值甚至以指针为函数参数都需要修改引用计数,这样的效率是很低下的。不过它的好处就是一旦有垃圾就马上收集,可以用于内存紧张的地方,不像Google的V8引擎这么耗内存。
Tracing
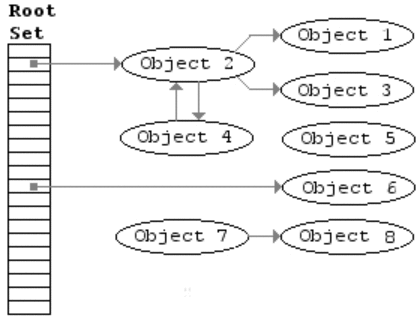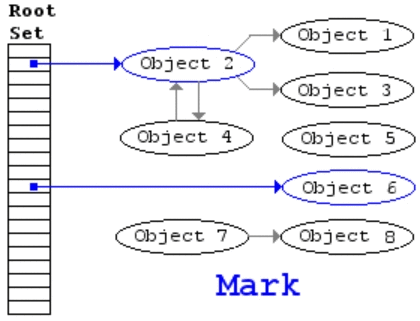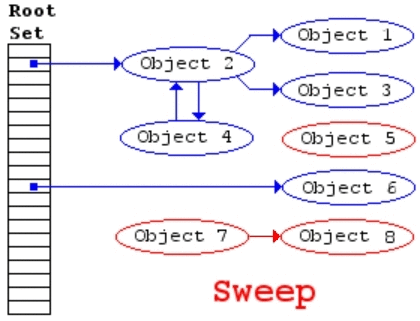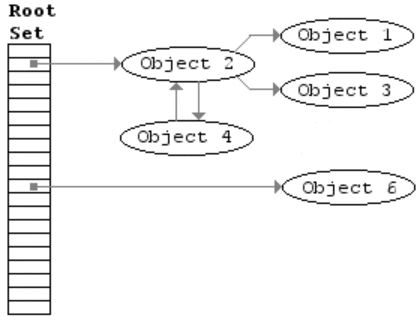
另一种方法是通过探测哪些堆上的对象再也无法被引用来进行垃圾收集,由McCarthy(Lisp创造者)提出。它的基本理念是:从“根”开始遍历所有能被根引用的对象,并进行标记,完成后再遍历所有堆上的对象,那些没有被标记的对象就是无法被程序引用的垃圾,可以将他们回收。这就是Mark and Sweep算法,见上图。
但是该算法有个麻烦的地方就是需要找出“根”。所谓的“根”就是可以引用堆上对象的指针,所以程序需要扫描整个程序的bss段,data段和stack段,并找出那些看上去像指针的值(所谓看上去像就是值在堆的地址空间内,并且符合一定的对齐标准)。这样需要扫描的实现就叫保守式gc,因为它并不精确定位每个指针,这种实现方法就非常适合做C语言库。最出名的库就是Boehm-Weiser GC,它的实现有两个优化:
- 将堆置于内存的高地址,这样很少会有程序的整型值会是合法的堆地址。
- 假设所有符合对齐的值就是堆地址
这种Tracing的方法可以避免reference count算法所无法识别的环状垃圾,所以某些reference count算法会有些优化来识别环状垃圾,而这种优化就是使用和tracing类似的方法。
两种算法的关系
这样初看起来两种算法似乎没有什么关系,但是这篇论文(感谢lisp聚会上的liancheng提供)提到了这两种算法共享了一些最基本的结构。而其他所有GC算法只是为了时间或空间上的trade-off而结合两种算法。
实际上,这两种算法最终都是要求出每个对象的精确引用计数(可以将tracing算法的标记当作退化了的引用计数),只是tracing算法倾向于低估对象的引用计数(在mark阶段初始化为0),而rc算法倾向于高估对象的引用计数(被引用计数为0的对象引用的对象的RC高于真实的RC)。并且tracing算法跟踪“活”对象的引用计数,而reference count算法跟踪“死”对象的引用计数(一旦某对象的引用计数为0就递归减少所有该对象引用了的对象的引用计数)。
所以所有的GC算法的最终不同就是存储区域的划分和维护真实RC的方式的不同,在做出这些设计决定后就只是一些空间、时间的trade-off了。