我们现在在做一个安卓应用的分析,需要读取apk文件,再通过工具分析成一个抽象语法树(以下简称为A树),之后再做一层和编译器相似的翻译,将A树翻译成我们的抽象语法树(以下简称为B树)。和java类似,apk中每个类都生成一个文件,而我们处理的单位也是这样的文件。为了模块化我们把分析和翻译分成两个独立步骤,所以分析函数和翻译函数的产出是一个装着各自结果的链表。
现在为了验证树的正确性,我们写了个B树的输出,再打包回去运行。所以我们总共有三个分开的步骤:分析、翻译和输出。
对于一些小型的apk这样做没什么问题,但前几天测一些大应用时会因为OOM挂掉,后来把jvm虚拟机堆大小设成2G才不会挂,拿工具看了下运行时的内存消耗峰值快达到1.5G,如下图
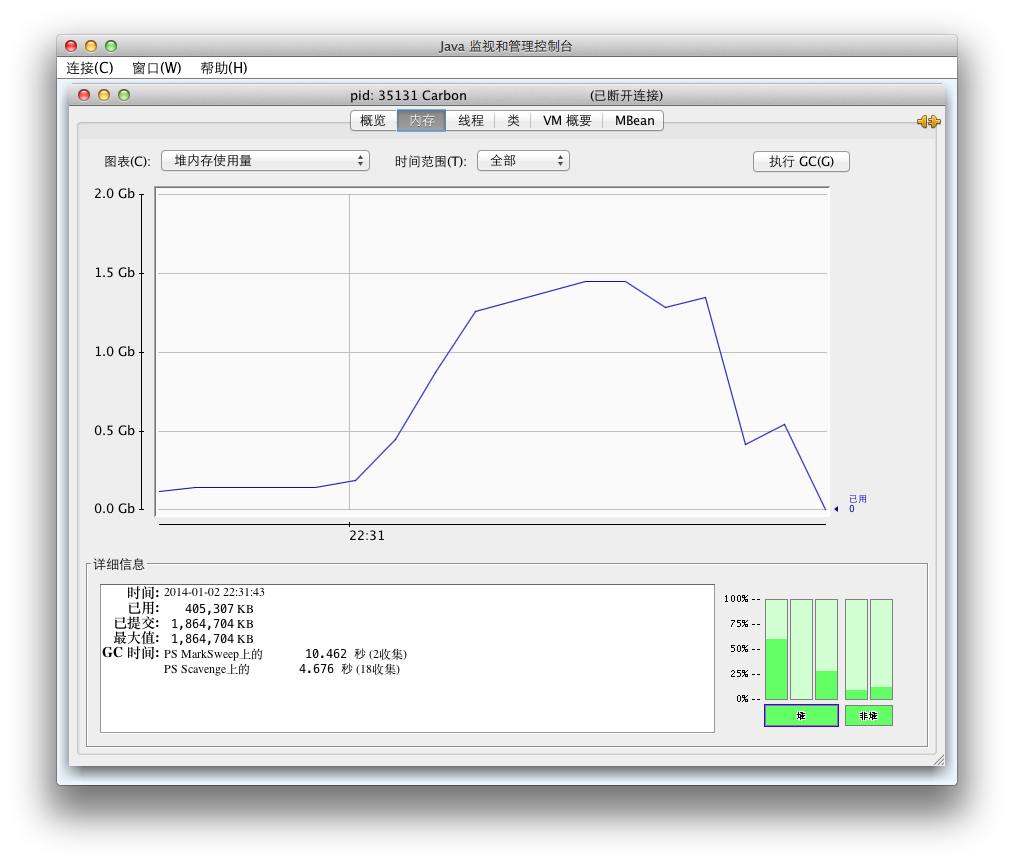
本来耗点内存也就算了,懒得调,不过之后我们准备批量测试apk,而跑测试的机子才2G内存,稍微跑大点的apk就挂可受不了。 之前也试了各种各样的优化方法,比如在翻译过程时破坏性地访问A树所在链表,翻译出一个B树就将相应的A树删除,或在链表没用后马上赋值为null。但是这种优化并没有带来很多效果,内存消耗还是很大,后来有人说应该将这两个独立步骤合并,因为我们现在的目的只是输出B树,所以可以写一个独立的函数,一次一个地分析出A树并马上翻译成B树再输出,这样内存中同时存在的树最多就两个文件产生的树,而不是之前的一个项目所有文件产生的树,内存消耗就会大大减少。
但是总觉得这样的做法并不优雅:需要维护两个内容基本相同的模块,而且目的变了后之前代码完全没法复用。最好的方法就是在不增加冗余代码并且不修改大体框架的情况下实现这种优化。
昨天晚上又看了看整个框架,发现这种流程不就是lisp里面的map么:先以解析函数和文件的链表作为参数传给map,将翻译函数传给map再过一遍之前的输出,之后把输出函数传给map再过一遍前面的输出。
想到map我就想到了之前被clojure的惰性map坑过一次:将函数传给map,之后一直等它输出却没有任何反应,调了很久才发现原来是惰性的问题。突然发现惰性求值不就是我们需要的么:可以将解析函数处理成惰性的,把翻译函数也处理成惰性的,在输出阶段再打破这种惰性就行了,因为只有到了输出阶段才真正地需要树的结构。这样一来我们之前的架构也可以在基本不修改的情况下使用这样的优化,更妙的是这样的架构之后也能复用,只有在真正需要树的情况下再打破这种惰性即可,这样不管以后的目的如何都能保证在内存中不会完整保留整个项目的树结构,除非真正用到整个树,即使访问了整个树也可以根据需求释放内存,像输出的这种情况,输出后就将对应的树删除即可。
优化点想到后实现了下,删除了100多行,增加了60多行就实现了,而且效果惊人,内存使用的峰值从1.5G下降到500M。如下图
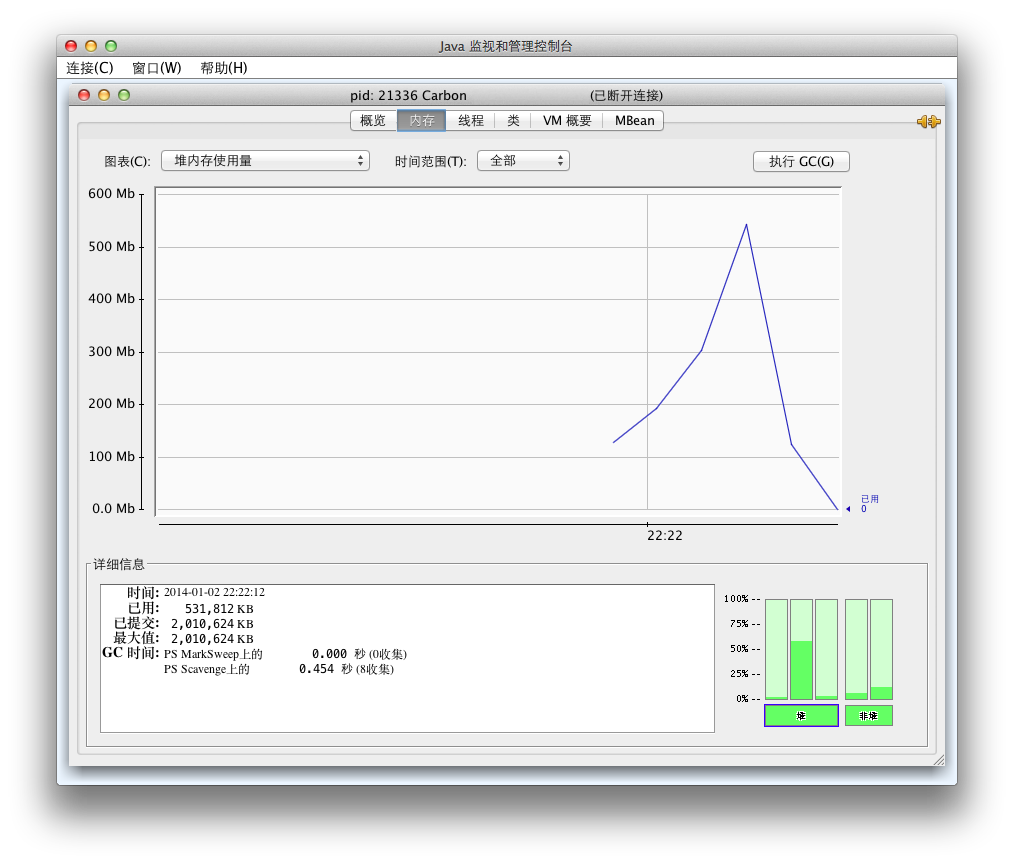
实现之前还想自己写个接口做这种惰性求值,后来发现Callable和Runnable接口就能直接拿来干这事,打破惰性时还能直接扔给ExecutorService多线程跑。
这是迄今为止我做优化最成功的一次了,不仅效果惊人而且还挺优雅。以前做优化都什么效果,有的优化后甚至还差了。看来以后还是得真正了解到优化点并且有比较优雅的解决方案时再着手优化,否则不仅效果差而且最后丑到自己都不想看了。