最近因为各种各样的原因对分布式感兴趣了,其中有一个就是在看w君学校里面分布式系统的课(我们学校竟然不开这个我最想上的课,真是悲哀)。已经看了里面提供的几篇论文还有笔记,觉得确实不错,值得推荐。其中一篇Lamport的论文让我觉得比较新鲜——在没有引入任何物理时钟的情况下定义了分布式系统的全序关系,这种方法应该很适合分布式系统的调试,因为可以清楚地知道A事件是不是比B事件发生得要早之类的。更让我觉得新鲜的是这种CS论文一半的引用竟然都是物理的相对论。
不过这篇博客要说的并不是那篇论文,而是另一个描述内存一致性的文献,一个分布式系统的课引用多核系统内存一致性的文献这个问题本身也挺有意思,因为它们有些问题在本质上是一个问题。
Sequential consistency
编程在很大程度上都是需要理解下层系统提供了一个什么样的模型或语义,比如Linux的C程序员就需要理解Linux的虚拟内存,Web程序员需要理解HTTP提供的语义。
所以我们就先从模型开始,对于编程最直观的一个模型就是程序是按序执行的,这样上层程序员就能很好地理解程序的行为,但是对于下层的实现来说这种要维持这种模型有两种方法,一是真正这么去做,二是只是维持语义的一致但并不是真正这样做的。不真正地顺序执行就是因为这样对于优化太不友好,一个最简单的例子就是global = 1; local += 1,其中global引用的是主存,而local只是寄存器变量,根据存储层次的效率,第一条指令需要执行100ns,但是第二条指令几乎只需要基本的一个指令周期就能完成。而且更重要的是这两条指令完全没有相互的依赖关系。为什么不并行执行呢?所以一般CPU都部署了一个write buffer,只要将global的值写入buffer就当做这条指令完成,继续执行下条指令即可,之后write buffer再写回主存即可。之后的读如果是和写同样的地址只需要返回write buffer中的值就行,如果不同那必须再次访问主存(可以不等待write真正写入主存,因为它们互相不依赖)。这种优化在单核(非分布式)系统上是满足了Sequential consistency的,但是对于多核(分布式)系统就没满足了,因为编程时不仅仅只是地址相同数据就相关,有时候多个数据多个地址在程序中也是相关的,但是CPU没法看出来,一个实例程序如下:
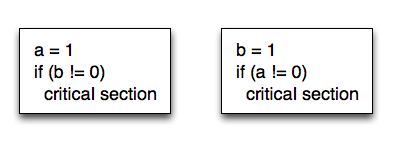
一开始a和b的值都是0,如果CPU都是按顺序执行没有上面的优化,那么只可能有一个线程进入临界区,但是如果有优化就有可能发生两个线程都进入或者都没进入临界区的情况。
所以只要下层支持Sequential consistency这样的模型,就不会让上面的程序出错。虽然这种模型简单,但是对于性能确实不友好,因为大部分情况下不同的变量确实不互相依赖,只有少数的情况依赖,所以一般的CPU并不支持这种模型,而支持更加宽松的模型,然后提供一个内存栅栏的机制支持上面程序的语义,对于那些宽松的模型的讨论直接看那个内存一致性的文献,这里就不讨论了。
实现
文献中提到要实现这种编程模型只需要支持下面两点就行:
- 处理器必须保证后一个内存访问必须在前一个内存访问结束后才能进行,而且对于有cache的系统,写操作必须向其他cache发送invalidate或update消息,而且直到收到所有的确认才算真正完成写操作。文献中把这叫program order requirement。
- 这个要求只是有cache的系统才需要满足。它要求对于同一个地址的写必须序列化,而且对这个地址的读必须要等写操作产生的invalidate或update消息都被确认了才能返回。文献中把这叫做write atomicity requirement。
chubby论文中描述的cache就是满足这样的模型的,因为这样的模型更加易于理解和使用。而且chubby的定位并不是高性能而是强调可靠和可用性,所以使用这样的模型也是有道理的。